Regulatory Accelerator
Data and AI, IBM Design
2018–19
Using machine learning to help data stewards ensure compliance with regulations.
First, let’s meet Dominick

Dominick’s roles and responsibilities
Dominick is a data steward who helps ensure his organization is compliant with government regulations.
How he does it
When new regulations come in, he keeps track of the regulatory terms and merges them with his business glossary. Dominick manually compares the terms and decides what's similar, what's not, and what needs to be adjusted.
Where he runs into trouble
His work is pretty tedious. Because a regulation could define something differently than the way Dominick's company does, it makes for a sticky situation. There's a lot of pressure on Dominick to get it right or else risk hefty fines for non-compliance. And since he has to review all of the documents manually, his current process could take months.
In his words
“[The process] is all very prone to human judgment and error. There are also too many terminologies to handle at once. There could be thousands of terminologies—even ones with overlapping meanings.”

We set out to help make Dominick’s task of comparing regulatory terms to business terms easier, faster, and more accurate with machine learning.
The team
Myself – UX + Visual Design
Justin Park – UX Design
Rachel Miles – User Research
Han Xia and Jen Cai – UX Design Interns
Duration
5 months
Outcome
🚀 Shipped as an add-on to IBM’s data and AI platform, Cloud Pak for Data
Project kick-off
Working from proof-of-concept
With Dominick’s pain-points in mind, a team of developers created a machine-learning model that extracts terms from a regulation and compares them to terms in a business glossary. But they needed help to integrate this model into a usable product that satisfied Dominick’s needs.

AI Workshop
To quickly get up to speed, we hosted Jennifer Sukis, design director for AI, to lead an AI Design Camp. We invited our stakeholders, including our design and development leads.
To prepare for this workshop, we gathered as much information on Dominick’s role from existing research in the Data and AI portfolio and interviewed three subject matter experts.
Ideation
During our workshop, we mapped out Dominick’s existing workflow, identified his biggest pain-points, and ideated on ways we can use machine learning to help. Here’s a snapshot from our ideation session:
Grouping and prioritizing ideas
We grouped our ideas into categories and then took another look at Dominick’s current workflow to determine where we could best integrate them, based on their overall difficulty to implement as well as their value to Dominick.
Here’s some of the ideas we thought were most valuable and served as jumping off points for our initial sketches:

Initial Sketches
Basic flow
By the end of the workshop, we had a basic concept of how Dominick would work within a project.


User research 🔎
After the workshop, we immediately wanted to get feedback from users and validate our direction.
Goal
Gain insight into users’ current mapping process and test our assumptions on the flow and order of operations.
Method
Hosted 1-hour moderated session with 4 users, during which we asked open ended questions to get overall impressions as they walked through a mid-fi prototype.
What we asked 💬
“What information do you need to know about a term in order to map it?”
“How many terms do you deal with at a time?”
“What happens when you aren’t familiar with a term?”
Iterations
At this point, we also split the work amongst our team: my focus became how Dominick would initially create a new project and how he would map terms within a project.
Creating a regulatory project
A quick start
We reduced the steps to creating a project to four. From there, users can begin mapping terms right away or add more details—including other team members and their term assignments and the project’s timeline.


Mapping to the business glossary
First iteration
My first iteration included information we knew: the name of the regulatory terms and the names of the business terms that matched. My main research question was: what else would users need to know in order to map terms?
What we heard
Users found the confidence scores helpful, but they wanted to see more context about both the regulatory term and the suggested business terms.
Users also said they would more likely be familiar with their business terms rather than the regulatory terms.


Creating a comparison view
With this in mind, my next iterations focused on building a comparison view for the user.
I changed the layout to be side-by-side, allowing the user to easily glance between the two sections with minimal scrolling.
I added descriptions to both terms and more context to the regulatory term, like how many times it appears in the regulation and where.
Designing with machine learning
Levels of automation
It was important for us to determine the level of automation that would be most valuable to our users. That is—enough automation to help users accomplish their task, but not so much that they feel a lack of control.
What does “confidence” exactly mean?
After probing users on the confidence scores, we discovered a conflict: Yes, they were helpful to order the list of suggestions, but what did they mean? Was 84% a bad score when there were 10 terms above 90%? Was 50% a bad score when it was the only term suggested?
Ultimately, users concluded that they would get a better sense of how to judge the confidence scores the more they worked with the tool.
Pre-selecting the best matches
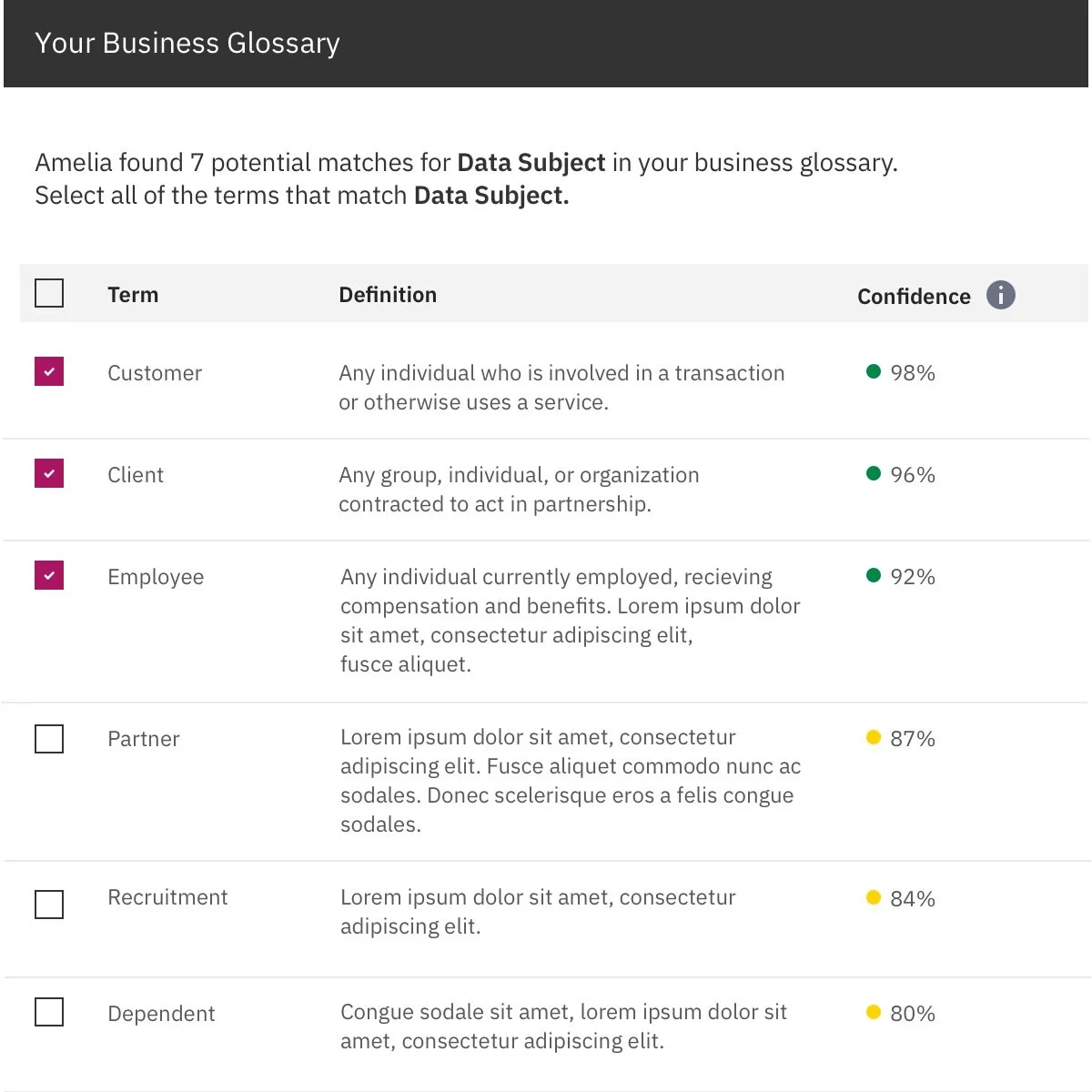
Our automation solution: when mapping, terms with 90% confidence or above would be pre-selected. This helped users map faster, but kept them in control.
We also allowed users to change this threshold as they see fit, depending on the model’s performance and the type of project.
Final design
Getting started
When creating a project, users first choose their industry to narrow their regulation options.
Project dashboard
Within a project, Dominick can see his unmapped and mapped terms. The primary action—continue mapping—uses color to call attention and is positioned on the right half of the screen to indicate progression.
Mapping terms
Dominick can see his progress and the current term he’s mapping. He can easily compare terms from CCPA to his business glossary in order to find the best matches, aided by the machine learning model’s pre-selections.
Considerations
While I was quickly put on another product after this shipped, I would have liked to track how the sense of trust in the machine learning model evolved with users.
I also would’ve liked to address scalability in the designs—adding list views or advanced pagination for cases where users have hundreds of terms.
A big thank you 👏
Thanks to the rest of the team on this one!